This article shall give an overview of various popular multi-tenant database patterns and their pros and cons - through a SaaS lens. That means that we analyze the patterns in terms of their suitability for SaaS applications and their tradeoffs. While there are many good posts already available on the internet, I want to bring together different naming conventions and patterns in one place, for a better overview and comparison.
An example use case
Let’s assume we have a SaaS application that helps customers organize their employees and machines. For the sake of brevity, it will consists of a web client, a backend API and a database. It could look like this:
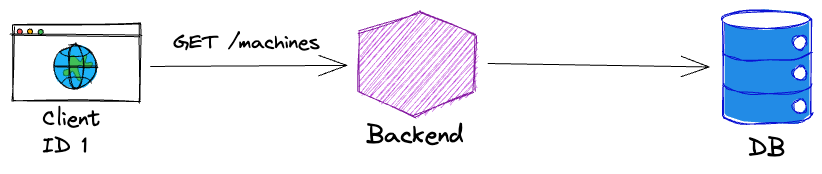
The various scopes of multi-tenancy
Taking a look at the example application, one can imagine that there might be different scopes of multi-tenancy and that is absolutely true. At the highest level (think of zoom level = 0), we can distinguish between single-tenant and multi-tenant systems, simply meaning that a system is either used by one tenant or multiple tenants:
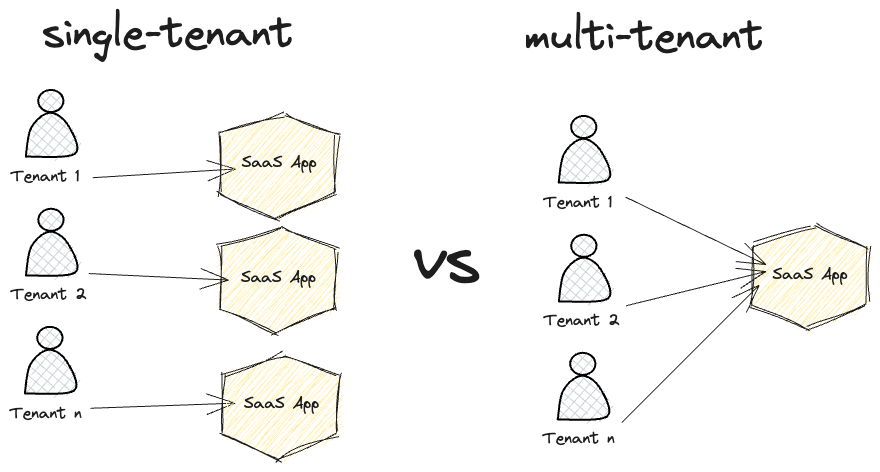
At the next level (zoom level = 1), we can distinguish between multi-tenancy applied for the backend, the client or the database.
For example, you could have the entire stack (client, backend, database) be single-tenant, meaning that each tenant has its own client, backend and database. Here you essentially achieve the single-tenancy of Figure 1.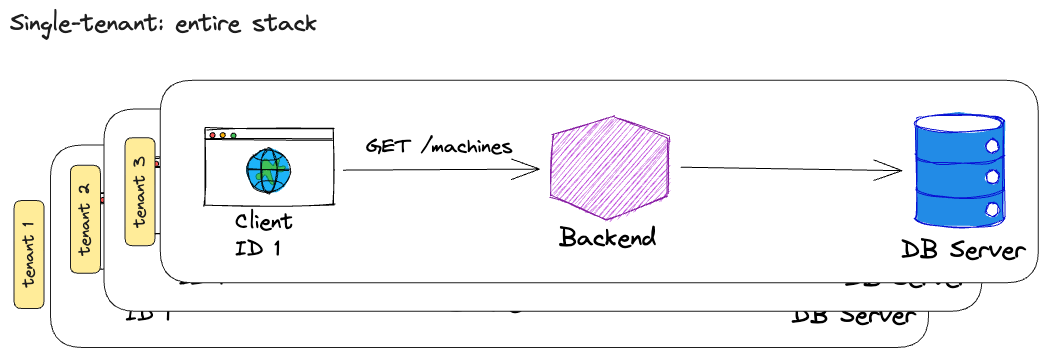
Of course, no one is stopping you from applying multi-tenancy on single components, like the backend only for example. Here it means, that some tenants get their own backend, but all tenants share the same database.
In other words, the backend is siloed per tenant, but the database is pooled.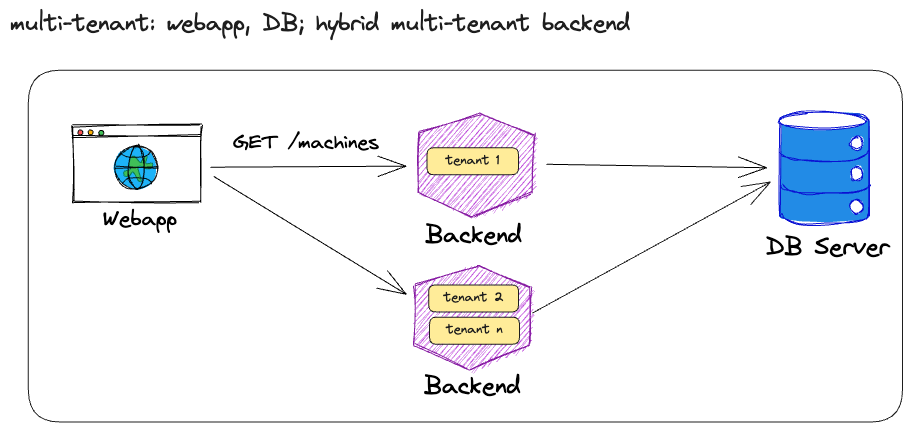
Since many cloud-native systems are built with stateless backends for scalability, we will focus on applying multi-tenancy on the database level in this article (zoom level = 2).
Terminology and the various ways of applying multi-tenancy
To get things started, let’s define some terms that will be used throughout this article. Please note that we focus on the data layer (database), so the terms are related to processing and storing data.
- Tenant: A tenant is a group of users that share the same database. Usually, a tenant is a customer of the SaaS application.
- Tenant ID: A tenant ID is a unique identifier for a tenant. It can be used to identify a tenant in the database.
- Single-tenant Database: A single-tenant database is a database that is used by only one tenant.
- Multi-tenant Database: A multi-tenant database is a database that is used by multiple tenants.
The patterns
As with nearly every software architecture topic, there is no one-size-fits-all solution. The same is true for multi-tenancy, so let the tradeoff-festival begin!
Pattern 1: Separate database server aka the silo pattern
In this shared-nothing approach, each tenant gets its own database server. This means that each tenant has its own database instance running which enables maximum isolation between tenants, thus eliminating the noisy-neighbor issue as well and possibly boosting compliance. This pattern is also known as the silo pattern. It also allows for maximum flexibility in terms of database configuration, since each tenant can have its own configuration. It strength is also its weakness, since keeping those different servers properly, configured, up-to-date, monitored and backed up is a very resource-intensive task. Surely Infrastructure-as-Code can help here, but it is still a lot of work. On top of increased complexity in terms of deployment and operation, this pattern also has a high cost, since each tenant needs its own database server. This pattern is best suited for large tenants that have high security and compliance requirements.
An implementation of this pattern could look like the image above (single-tenant stack) or like this, if you do not want to set up a dedicated backend API for each tenant as well: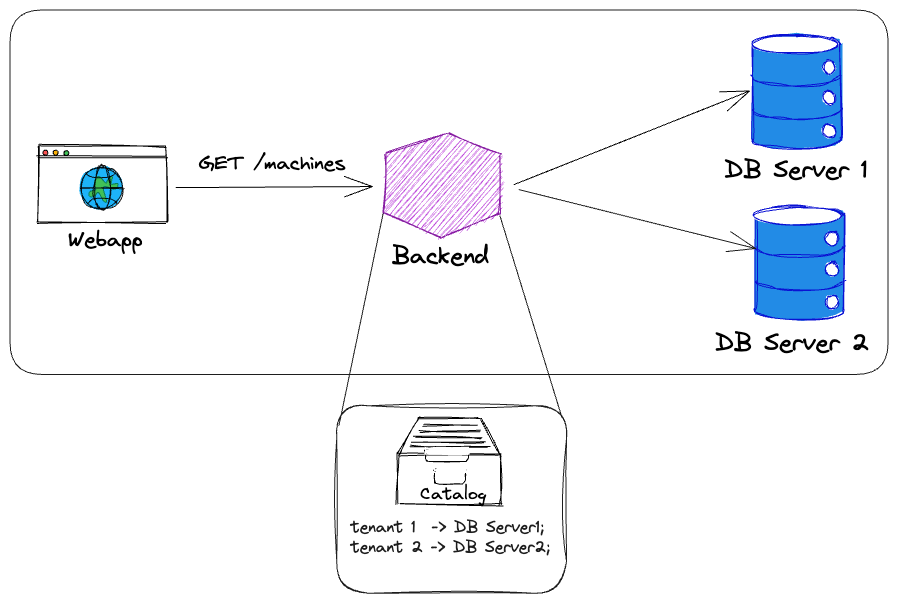
Please keep in mind that somewhere the mapping between tenant and database server has to be stored, so that the backend knows which database server to connect to for a given tenant. Those mapping/lookup components are sometimes called catalogs and could be a simple key-value store or a more sophisticated service registry. Designing a proper catalog is a topic for another article, but it is important to keep in mind that it is needed.
Pattern 2: Separate by schema or database
This umbrella term describes a pattern where multiple tenants share the same database server, but get their isolation by logical constructs e.g. having a dedicated database or schema for each tenant. This pattern is also known as the bridge pattern. By sacrificing some isolation, this pattern reduces the complexity and the costs of the silo pattern, since you do not need to set up a dedicated database server for each tenant. It also allows for customization, since each tenant can have its own database or schema. This pattern is best suited for tenants that have medium security and compliance requirements under certain conditions. It is really a hybrid model, where you can benefit or shoot yourself in the foot, depending on the requirements:
- it is isolated, but does not provide the same level of isolation as the silo pattern and does not eliminate the noisy-neighbor issue
- it has less infrastructure cost, but suffers from a all-or-nothing availability
- it is flexible and allows customization for tenant specific custom data , but deployment complexity is still high and needs to be thoroughly orchestrated with the backend deployment
Regardless of the logical construct used, the mapping between tenant and logical construct has to be stored somewhere, so that the backend knows which logical construct to connect to for a given tenant.
If using databases to separate tenants, it could look like this: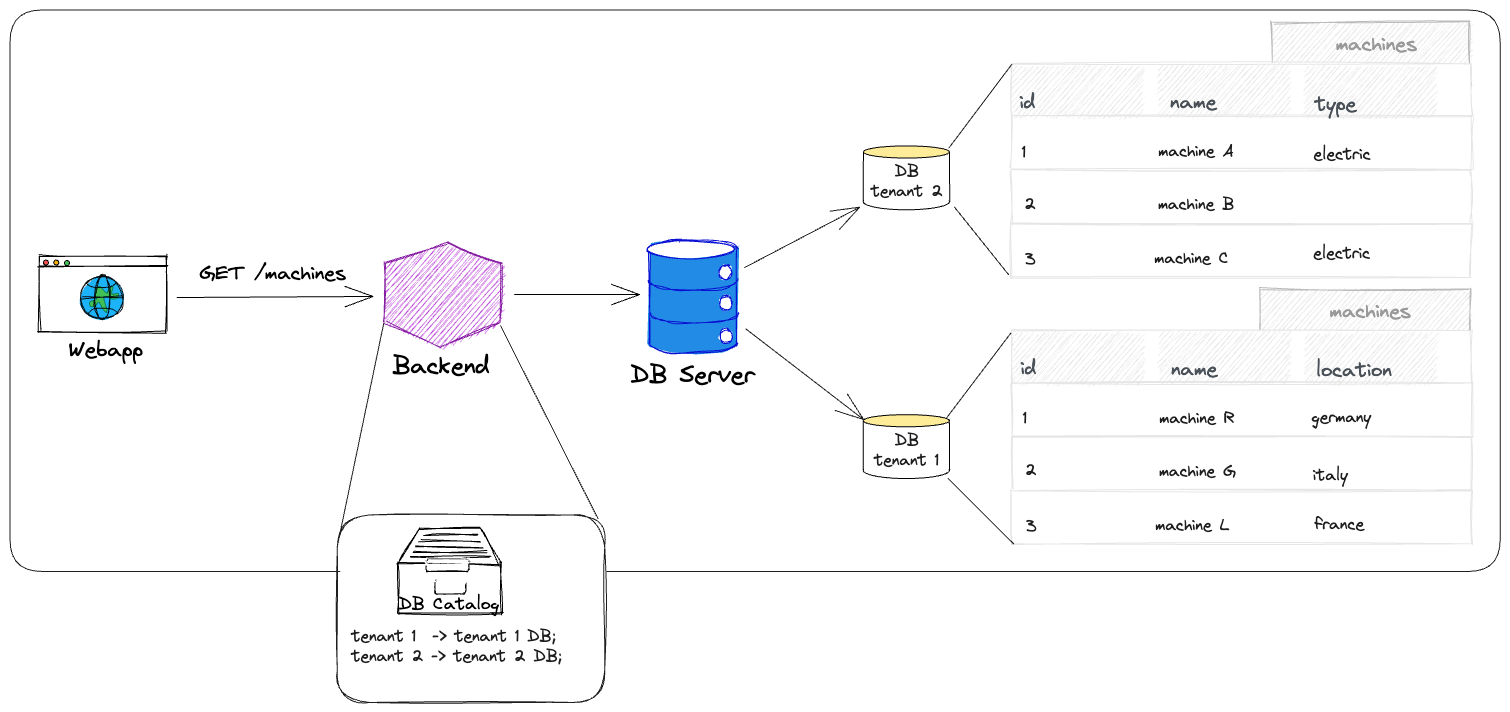
If you choose to use schemas to separate tenants, it could look like this: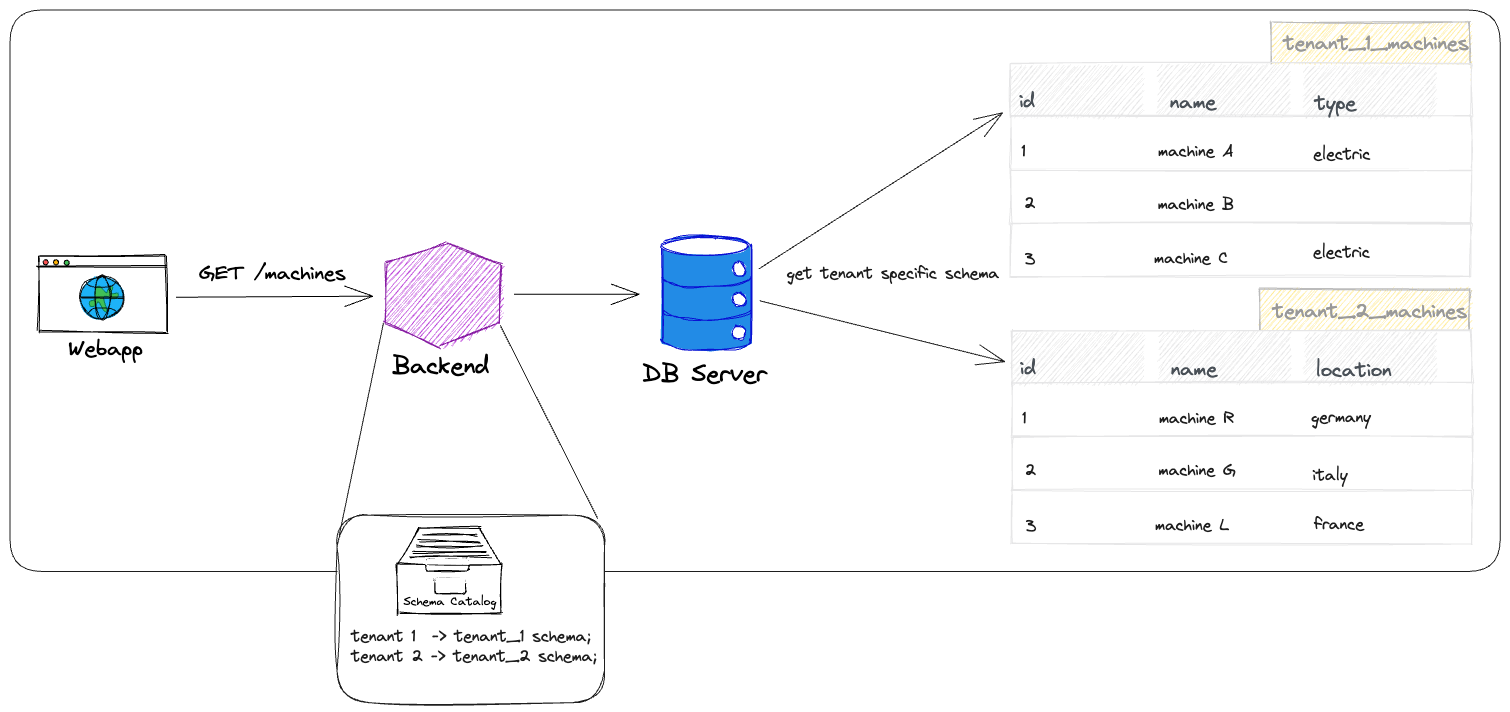
This pattern was used often in the past, as it offers higher agility and lower costs, than the silo pattern traditionally. Imho, these advantages are not as relevant anymore, since the cloud-native movement has made it possible to spin up new and manage database servers with much less overhead. Still, your team needs to have proper experience and resources if you need that extra control for performance tuning and isolation.
For even more agility, let’s take a look at the next pattern.
Pattern 3: Separate by table column
This pattern is also known as the pool pattern. It is somewhat similar to the bridge pattern, but instead of separating tenants by database or schema, it separates them by a table column. This means that all tenants share the same:
- database server/cluster
- database
- schema and tables
The isolation is achieved that each relevant table has an additional column like tenant_id that is used to identify and separate the data of different tenants.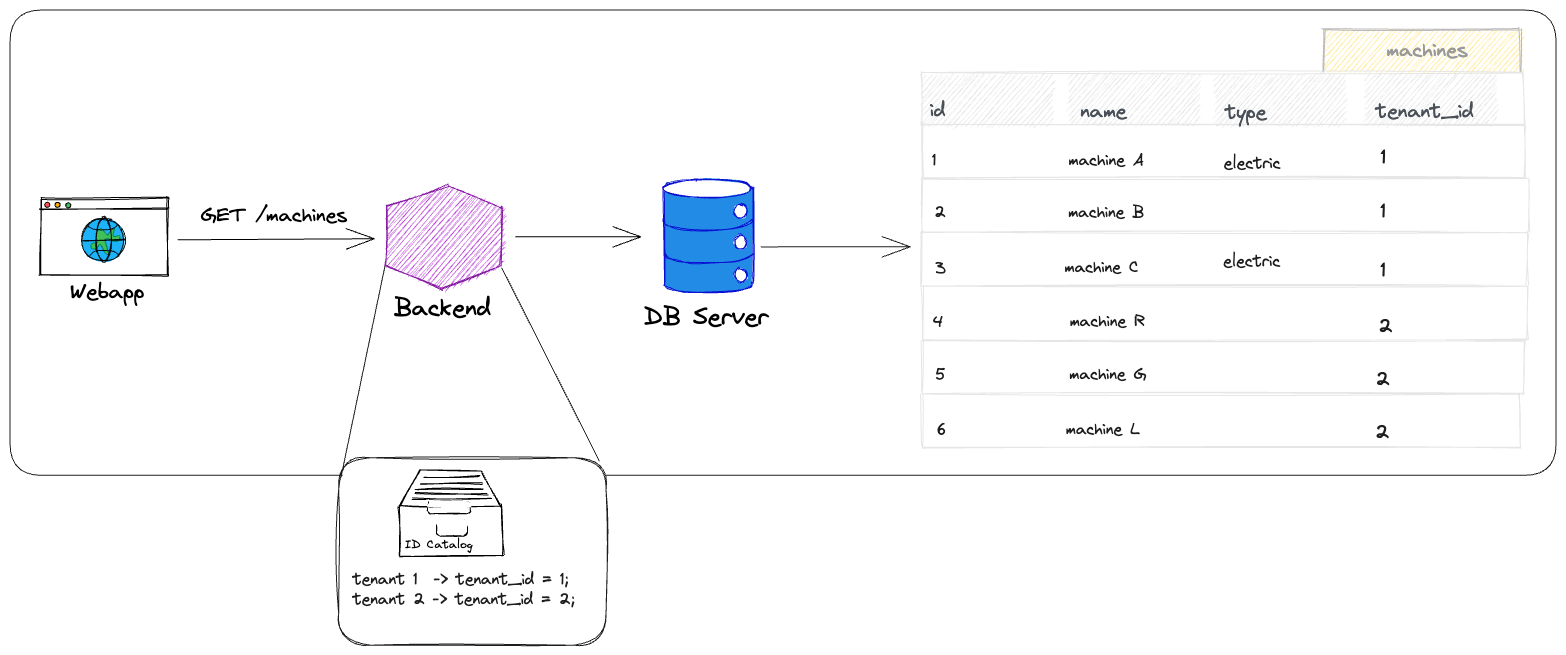
Note that a true catalog component is not really needed, as the tenant_id is very lightweight and no connection credentials need to be stored. Such ID can often be kept in a session or in the JWT token of the user.
Of course, there are obvious drawbacks that might make it unsuitable for your use case:
- isolation is achieved by a column, so it is not as strong as the bridge pattern and especially not as strong as the silo pattern
- per-tenant customizations are tricky, since you would need to add additional columns to the tables
- similar issues as bridge pattern:
- noisy-neighbor can be an issue
- all-or-nothing availability
- limited scalability
- complex per tenant backups and restores
But especially for SaaS-businnesses, there can be striking reasons to follow this approach once combined it with additional technologies:
- data isolation can be enforced with Row-Level-Security (RLS) in the database
- if customization can be kept at a minimum: achieve per-tenant customization can be achieved with JSON data types
- with sharding the data by tenant_id, scalability can be achieved (see Citus extension for PostgreSQL)
- It is very easy to add new tenants, since you do not need to set up a new database or schema
- It is straightforward to monitor
- unmatched agility in terms of deployment and operation
Conclusion
As you can see, there is no one-size-fits-all solution but more like a spectrum of solutions, ranging from maximum isolation to maximum agility. Depending on your use case, the following questions might help you to decide which pattern to choose:
- How much isolation do you need?
- How much agility do you need? Do you need to be able to spin up new tenants quickly? How often do you want to deploy?
- What kind of SLA or performance requirements do you have?
- Do you need to have precise cost monitoring/metering per tenant?
- How much customization do you need? Do you want to provide special features for each tenant?
- How much scalability do you need? Do you expects 10s, 100s or 1000s of tenants?
- How much resources and expertise do you have? Do you have a dedicated team/expert for database operations/devops?
- What kind of regulations do you need to follow? E.g. GDPR, ISO 27001?
What’s up next: For SaaS scale-ups however, the pool pattern can be often a good fit, since it allows for fast iteration cycles through fast deployments and operations. And as we’ve put on a SaaS lens, let’s keep those goggles and focus on the implementation and the mitigation of risks of the pool pattern in the next article.
Useful resources
- https://learn.microsoft.com/en-us/azure/azure-sql/database/saas-tenancy-app-design-patterns?view=azuresql
- https://docs.aws.amazon.com/prescriptive-guidance/latest/saas-multitenant-managed-postgresql/matrix.html
- https://learn.microsoft.com/en-us/azure/architecture/guide/multitenant/approaches/storage-data#databases
- https://renatoargh.files.wordpress.com/2018/01/article-multi-tenant-data-architecture-2006.pdf
- https://www.thenile.dev/blog/multi-tenant-rls
- https://aws.amazon.com/de/blogs/database/choose-the-right-postgresql-data-access-pattern-for-your-saas-application/